Design and Development of Medical Databases
의학 데이터베이스의 설계와 구축
Article information

Abstract
Since the Fourth Industrial Revolution was declared at the World Economic Forum in 2016, we have witnessed significant technological innovations across various fields. Artificial intelligence (AI) technology has developed alongside computing technology, algorithms, and platforms, but its most crucial foundation lies in data collection and management capabilities. This paper aims to share expertise gained through our experience in constructing medical databases, including the Hearing Big Data Center, Common Data Model implementation, and balance function test databases. We first explain the fundamental concepts of databases, distinguishing between structured and unstructured data, and introduce relational database models and data schemas particularly relevant to otolaryngology. We then describe practical strategies for designing and operating medical databases that can flexibly handle both structured and unstructured data, using hearing and vestibular function test data as representative examples. Additionally, we address important considerations for healthcare database construction, including privacy regulations, de-identification processes, and data combination techniques according to South Korean guidelines. Finally, we discuss how well-designed medical databases can be linked with AI and machine learning models, enabling multimodal analysis that integrates clinical data, imaging, and physiological signals. We argue that by understanding database design principles and proper data management approaches, medical researchers can more efficiently utilize vast medical data resources while maintaining patient privacy, ultimately advancing medical research and clinical practice in the era of AI.
Introduction
Since the Fourth Industrial Revolution was declared at the World Economic Forum in 2016, rapid technological innovation has become evident in the six core domains of big data, artificial intelligence (AI), robotics, the Internet of Things, unmanned aerial systems, three-dimensional printing, and nanotechnology [1,2]. In 2016, Google DeepMind demonstrated the capabilities of AI by defeating Lee Sedol, one of the world’s top Go players, with AlphaGo, highlighting AI performance in a domain traditionally regarded as requiring human intuition and creativity [3]. Tesla has similarly been recognized not only for advancing electric vehicles but also for pioneering AI-driven autonomous driving technologies that have transformed the automotive industry [4].
With the widespread introduction of generative AI, including large language models such as ChatGPT, AI tools are now routinely used to enhance productivity, functioning in many cases as virtual personal assistants [4]. Although the evolution of AI has been driven by advances in computing technologies, algorithms, and platforms, its most important underlying factor is the development of technologies for large-scale data collection and management [5]. Improvements in computing power and cloud-based infrastructures have enabled not only efficient storage and retrieval of vast datasets but also real-time data analysis and visualization [5].
These trends are often summarized by the “5V” characteristics of big data—Variety, Volume, Velocity, Value, and Veracity—reflecting the intention to collect and utilize heterogeneous data generated across diverse domains, including text, logs, and images, rather than focusing solely on large numerical datasets [6].
In medicine, particularly in otolaryngology, clinical data frequently take unstructured forms, such as hearing test results, vestibular function test outputs, radiologic and magnetic resonance imaging, and electronic medical records (EMRs). As a result, data structures and formats vary widely depending on institutions, devices, and testing protocols, leading to limited reusability from the perspectives of long-term research and AI development. Against this background, the authors have accumulated practical expertise through projects such as the Hearing Big Data Center of the Korean Audiological Society, Common Data Model (CDM) implementation initiatives, and the construction of vestibular function test databases related to dizziness. Based on these experiences, this article introduces design principles and concrete implementation examples for otolaryngology databases capable of simultaneously managing structured and unstructured data.
Understanding Databases: Structured and Unstructured Data
A database is conventionally defined as a collection of values represented as quantitative or qualitative variables [7]. In the era of big data, this definition has expanded to encompass data types that are difficult to classify strictly as quantitative or qualitative, including text, audio, images, and video. Nevertheless, meaningful data analysis requires that such information ultimately be organized into analyzable forms, underscoring the importance of understanding the distinction between structured and unstructured data [7].
Structured data follow predefined data models or schemas and are organized within systematic frameworks, allowing efficient searching and analysis due to their quantitative characteristics. Such data are typically stored in data warehouses using structured query language (SQL)-based relational database systems [7]. In contrast, unstructured data refer to all other data types that do not conform to predefined schemas and may exist as text, audio, images, or video. In otolaryngology and medicine more broadly, most diagnostic reports, imaging studies, and EMR-based clinical narratives fall into this category [8]. Although unstructured data offer flexibility, they are inherently difficult to search and analyze systematically due to the absence of explicit schemas [8].
Therefore, to integratively manage the diverse structured and unstructured data generated in otolaryngology, careful database design is required to determine how these two data types should be structured, linked, and utilized in a complementary manner [8].
Relational Database Architecture and Data Schemas
Since its initial proposal by Codd [9] in 1970, the relational database model has remained the most widely adopted database framework. In relational databases, data attributes of individual entities are represented in two-dimensional tables, and relationships between entities are defined using relational algebra and relational calculus. Fig. 1 illustrates an example of a relational database model in which “Student,” “Professor,” and “Course Offering” entities are represented as separate tables. Relationships between the “Student” and “Professor” entities are defined through a “Guidance” relationship using a shared “Professor ID” attribute, while course offerings and registrations are linked through departmental attributes. This structure demonstrates how relational databases organize entity attributes into concept-based tables with explicit relationships.
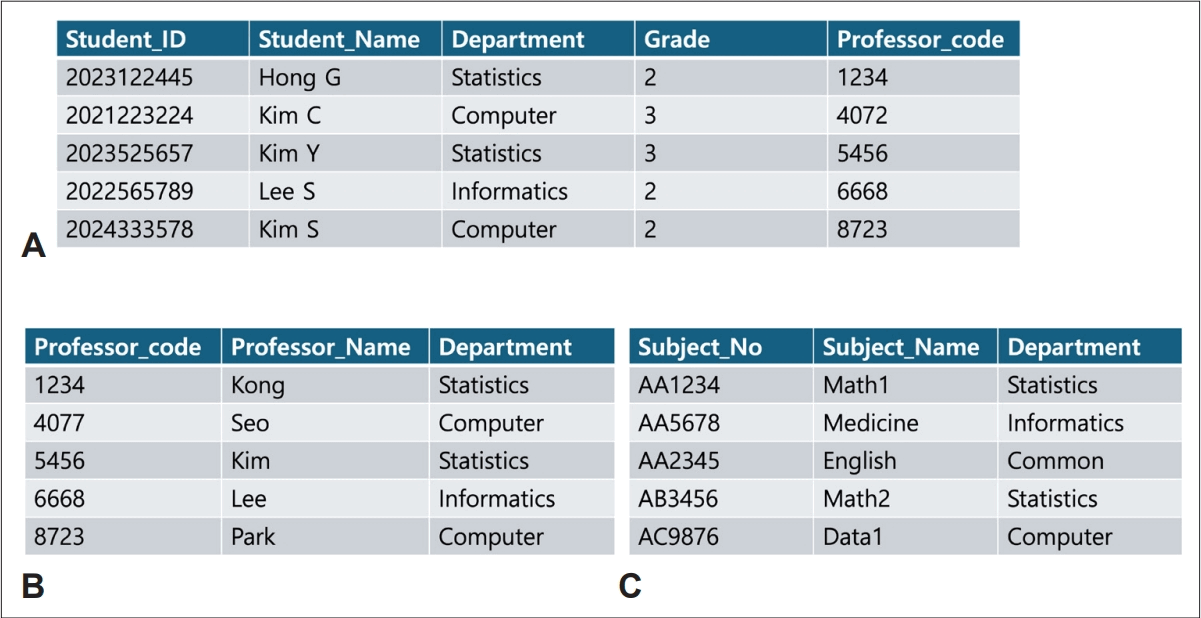
Example of a Relational Database Model. This figure shows an example of a relational database model displaying the relationships between “Student,” “Professor,” and “Course Offering” entities in database tables. The relationship “Guidance” connects the “Student” and “Professor” entities through the “Professor ID” attribute. Additionally, relationships of course offerings and registrations exist among the “Student,” “Professor,” and “Course” entities, with the “Department” attribute serving as the connecting link. This illustrates how relational databases organize attributes of each entity into concept-based tables with defined relationships. A: Student Table. B: Professor Table. C: Subject Table.
A data schema provides a comprehensive specification of database structure and constraints. It defines attributes, entities composed of attribute sets, relationships among entities, and integrity constraints that must be maintained [7]. In relational databases, the relational schema is an essential design element, as it explicitly defines how entities and their relationships are structured, ensuring data consistency, integrity, and extensibility [7].
Medical Database Construction: Otolaryngology Cohorts and Hybrid Architecture
Many researchers construct datasets to test specific research hypotheses; however, building databases solely for single hypotheses is inefficient [10]. Consequently, disease-specific prospective or retrospective cohorts are often established and reused as databases. Such cohort data are frequently stored as spreadsheet-based case report forms, which limits scalability and long-term usability from a database design perspective [10].
During the construction of the Hearing Big Data Center in 2020, the authors designed a relational database and data schema with a simple yet highly extensible structure (Fig. 2). This database integrated approximately 120000 pure-tone audiometry (PTA) records, over 8000 speech audiometry tests (SRT/WRS), tens of thousands of diagnostic codes, and associated metadata. Because audiometric test sheets varied widely across institutions and were largely unstructured, direct storage of raw formats would have hindered SQL-based analysis. To address this, thresholds were manually digitized, patient and test tables were linked in a one-to-many structure, and frequency-specific thresholds were stored in a long-form format. This design supports future extensions—such as additional frequencies, bone and air conduction data, and masking information—while maximizing analytical efficiency through SQL-based queries.
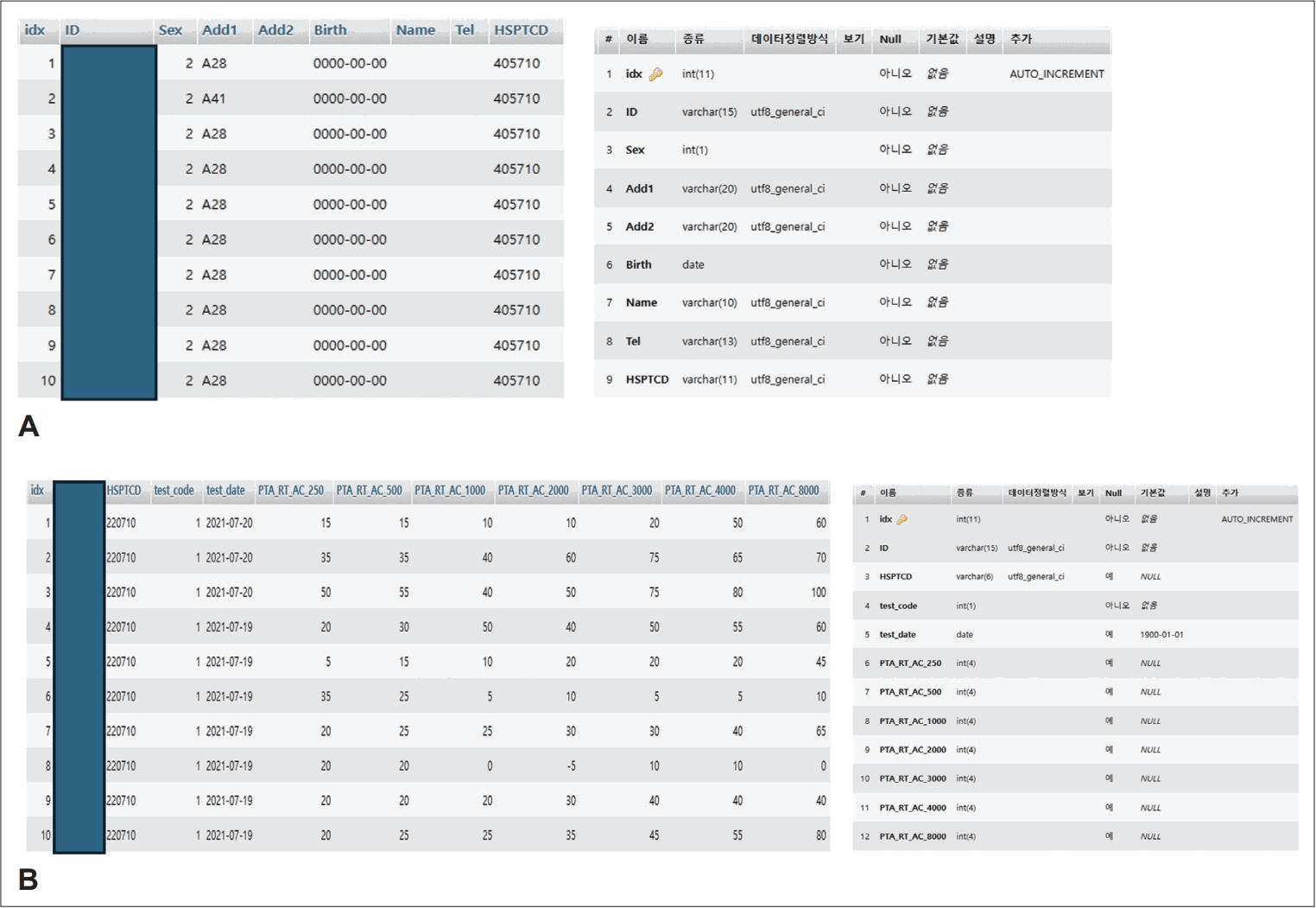
Relational Database and Data Schema for Hearing Big Data. This figure illustrates the relational database and data schema designed for the Hearing Big Data Center Although the structure is simple, it provides significant extensibility. This relational database design offers advantages in terms of extensibility and integration when additional clinical information (e.g., vestibular function test data, general disease data such as blood tests) is added for patients included in the database. A: Profile table. B: Pure tone audiometry table.
For vestibular function test data, which inherently include large volumes of unstructured data, a two-tier hybrid storage system was adopted [10]. The first tier stores raw video and signal data in S3-compatible object storage, with SHA-256 hash values preserved to ensure file integrity and access controlled through secure URLs. The second tier consists of structured metadata tables defining clinically relevant parameters, such as saccade latency, gain, slow-phase velocity, and nystagmus direction for videonystagmography (VNG); gain, asymmetry, and catch-up saccades for video head impulse testing (vHIT); P13/N23 latency and amplitude ratios for cervical vestibular evoked myogenic potential (VEMP); and deviation angles and trial variability for subjective visual vertical testing. This hybrid structure allows unstructured data to be accessed only when necessary, while structured parameters are readily available for SQL-based statistical analyses and AI feature engineering [11].
To optimize query performance, B-tree indices were applied to frequently queried attributes such as patient identifiers, visit dates, test types, and PTA frequencies, with auxiliary indices created for foreign keys to improve join efficiency. Materialized views were employed to reduce repetitive computations, and lazy-loading strategies were used for large unstructured components. Backup strategies combined daily full backups with hourly incremental backups, supporting point-in-time recovery through write-ahead log retention. Domain constraints were applied to key parameters to ensure data integrity, with automated alerts triggered upon violations.
General Considerations for Healthcare Database Construction
Healthcare data, including those generated in otolaryngology, are inherently sensitive personal information and must be handled accordingly. In South Korea, healthcare data utilization guidelines were first established in September 2020 by the Ministry of Health and Welfare and the Personal Information Protection Commission and have been continuously revised, with the most recent update issued in December 2024 [12]. Researchers must ensure that healthcare data are used in compliance with privacy laws and must distinguish between pseudonymized and anonymized data. Pseudonymized data are processed through techniques such as deletion or replacement of identifying information to prevent direct identification, although re-identification remains possible when combined with additional information [12].
Anonymized data, by contrast, are processed so that individuals cannot be identified by any reasonably available means; however, this often results in substantial loss of demographic information, limiting clinical utility [12].
Security, Access Control, and Audit Logging in Healthcare Databases
Security and privacy protection are paramount in medical database construction and operation. The authors implemented a multilayered security approach. First, role-based access control and the principle of least privilege were strictly applied, differentiating permissions among principal investigators, analysts, and system administrators. All access activities were recorded through automated SQL-based logging and reviewed during monthly security audits.
Second, the Hearing Big Data Center was operated within an air-gapped environment to prevent external network access when analyzing identifiable data. Data export required automated difference checks and dual authorization by security officers. Third, strong encryption mechanisms were applied during data storage (AES-256) and transmission (TLS 1.3). Unstructured data stored in object storage were governed by bucket-level access policies and accessed only through short-lived presigned URLs.
Fourth, re-identification risk assessments were conducted using k-anonymity criteria (k ≥5), with additional pseudonymization measures applied when risks were identified. Finally, audit and anomaly detection systems were implemented to monitor abnormal access patterns, including exploratory application of machine learning-based intrusion detection models.
Considerations for Pseudonymization and Data Combination
Pseudonymization is a critical process in medical database construction and analysis. Although pseudonymized data may be processed without individual consent for statistical analysis, scientific research, and public interest purposes, strict procedural safeguards are required [12]. Pseudonymization begins with clear definition of data use purposes, followed by assessment of identification risks and application of appropriate technical and administrative protections. Additional information, such as encryption keys, must be stored separately and destroyed when no longer required.
Data combination can enhance scientific and public value but increases identification risk. Therefore, all data linkage must be performed in controlled environments, with additional pseudonymization applied to combined datasets. Linkage keys must preserve relational integrity while preventing individual identification, and repeated linkage requires reassessment of identification risks at each stage. These procedures balance efficient data utilization with the protection of data subjects’ rights.
Examples and Scalability of AI Model Applications
The constructed database integrates both structured and unstructured information, enabling diverse AI applications. Structured data support feature engineering for predictive models of hearing thresholds and prognosis, while visit-level organization facilitates time-series modeling using recurrent or transformer-based architectures. Unstructured data, such as VNG videos and vHIT raw traces, can be used to develop deep learning models for nystagmus pattern recognition and catch-up saccade detection. Speech recordings of symptom descriptions may be converted into text and processed using natural language processing embeddings.
Moreover, the database is well suited for multimodal AI models. By organizing structured test results, imaging and signal data, and clinical text into time-ordered JavaScript Object Notation-based timelines, multimodal transformer models can be implemented to improve diagnostic and prognostic performance [13]. Automated Extract, Transform, Load pipelines were developed to extract structured data via SQL and access unstructured data securely using presigned URLs, with standardized terminology mapping to systems such as SNOMED and LOINC to ensure analytical consistency.
Finally, portions of the database were designed to be compatible with CDM frameworks, facilitating future multicenter collaborations and standardized analyses. Ongoing international efforts toward data standardization in audiology and vestibular research highlight the importance of such interoperability [14,15].
Conclusion
In the era of AI, understanding data science and database design is fundamental. Medical databases must be constructed using systematic designs that efficiently manage structured and unstructured data while ensuring scalability and standardization. At the same time, strict adherence to privacy protection and pseudonymization principles is essential to preserve the value of medical data without compromising ethical responsibilities. Ultimately, thoughtful database design from a data science perspective will play a central role in advancing medical research and clinical practice. This article is intended to serve as a practical “how I do it” guide for otolaryngology researchers seeking to design databases tailored to their clinical environments and to expand them toward AI-driven and multimodal analyses.
Supplementary Materials
Korean translation of this article is available with the Online-only Data Supplement at https://doi.org/10.3342/kjorl-hns.2025.00122.
Notes
Acknowledgments
This research was supported by a grant of the Korea Health Technology R&D Project through the Korea Health Industry Development Institute (KHIDI), funded by the Ministry of Health & Welfare, Republic of Korea (grant number: RS-2025-25460099).
Author Contribution
Conceptualization: Young Joon Seo, Tae Hoon Kong. Investigation: Young Joon Seo. Methodology: Tae Hoon Kong. Project administration: Young Joon Seo, Tae Hoon Kong. Supervision: Young Joon Seo. Writing—original draft: Tae Hoon Kong. Writing—review & editing: Tae Hoon Kong, Young Joon Seo.